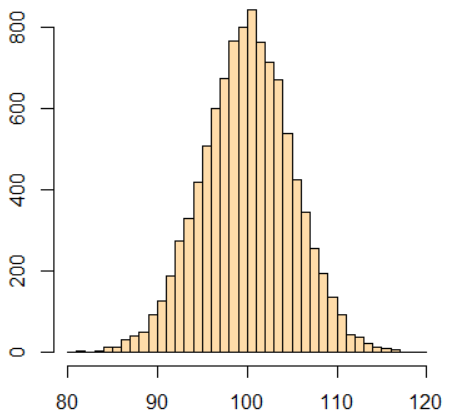
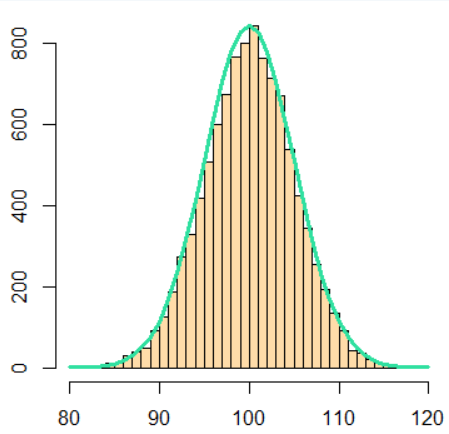
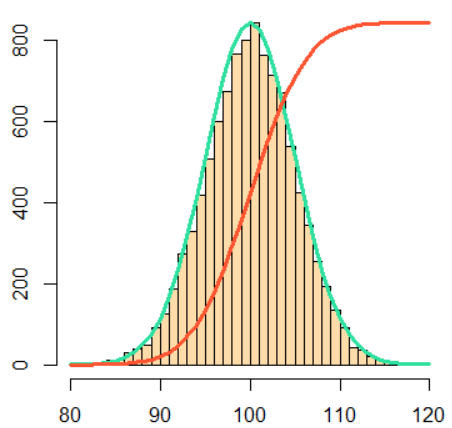
The d prefix stands for the probability density function (PDF).
The PDF is added onto the plot, showing that the shape of the histogram tends to converge to the shape of the PDF as the number of random variables increases.
dens <- dnorm(breaks_, mean_, sd_);
lines(
breaks_ ,
dens / max(dens) * max(hist_$counts),
col='#30e0a0',
lwd = 3
);